
W jaki sposób możemy zweryfikować problemy wydajnościowe w ElasticSearch?
- 27 lutego 2025
- W artykule dowiesz się:
- Case study na podstawie ElasticSearch
- Konfiguracja klastra ES na środowisku deweloperskim na potrzeby testów wydajnościowych
- Podpięcie klastra deweloperskiego pod Prometheus i wizualizacja na Grafanie
- Testy wydajnościowe na środowisku deweloperskim
- Analiza klastra ES na środowisku produkcyjnym
- Interwał indeksacji
- Garbage Collector
- Konfiguracja dodatkowego węzła w klastrze
- Propozycja innych rozwiązań w celu poprawy wydajności
- FAQ
- Porozmawiajmy
W artykule dowiesz się:
- jak podejść do analizy problemów wydajnościowych w klastrze Elasticsearch,
- dlaczego warto odtworzyć środowisko produkcyjne na środowisku deweloperskim,
- jak wykorzystać Prometheus i Grafanę do monitorowania obciążenia oraz czasu wykonywania zapytań,
- jakie dodatkowe działania mogą poprawić wydajność zapytań i stabilność systemu.
Case study na podstawie ElasticSearch
W poniższej analizie starano się znaleźć odpowiedź na problem dotyczący długiego przetwarzania zapytań SQL, zwłaszcza w określonych porach dnia, gdy system jest bardziej obciążony. Jednym z obszarów, który był analizowany, to poprawa efektywności w okresach największego obciążenia systemu. Badając problem przeprowadzono 7 różnych analiz długiego przetwarzania zapytań.
Działania zrealizowane w celu analizy problemów wydajnościowych w ElasticSearch.
Konfiguracja klastra ES na środowisku deweloperskim na potrzeby testów wydajnościowych
Uruchomienie w środowisku deweloperskim klastra ElasticSearch, który jest zgodny z parametrami i liczbą węzłów, jak środowisko produkcyjne. Celem jest przetestowanie obciążenia bazy danych i czasu wykonywania zapytań poprzez odtworzenie tych samych warunków. Jest to możliwe podejście w przypadku gdy mamy wystarczające zasoby a zarazem nie jesteśmy w stanie odtworzyć problemów w obecnym środowisku testowym.

Uruchomiony 3-węzłowy klaster Elasticsearch na serwerze deweloperskim
Zalecane jest również aby wdrożyć narzędzie Kibana dla lepszego dostępu do wizualizacji danych i narzędzi developerskich. W celu odtworzenia problemów, które występują w produkcyjnym środowisku warto przeprowadzić migrację produkcyjnej bazy danych – z możliwą anonimizacją danych. W przypadku bardzo dużych baz, prace najlepiej podzielić na etapy, a indeksy przenosić partiami.
Podpięcie klastra deweloperskiego pod Prometheus i wizualizacja na Grafanie
Dobrze jest podłączyć klaster deweloperski do usługi Prometheus aby realizować wizualizację danych na Grafanie. Testy wydajnościowe zaczynamy wykonywać na środowisku deweloperskim, zaczynając od analizy zapytań, które sprawiały problemy w określonych godzinach.
W opisywanym schemacie postępowania w trakcie testów można zebrać również wszystkie zdarzenia z danego przedziału czasowego. Statystyki uzyskane z przetwarzania problematycznych żądań, widoczne w Grafanie, niekoniecznie mogą odzwierciedlać problemy występujące w środowisku produkcyjnym. Nawet uruchomienie jednocześnie wszystkich zapytań jakie występują w środowisku produkcyjnym, bez określonego czasu, może skutkować szybkimi odpowiedziami z klastra ElasticSearch. W takiej sytuacji niezbędne jest przeprowadzenie dalszych testów.
Testy wydajnościowe na środowisku deweloperskim
Testy należy zacząć od sprawdzenia zapytań w problematycznym oknie czasowym.
W celu symulacji wzmożonej liczby zapytań przetworzyć można przy użyciu parsea i umieścić w automatycznych skryptach systemowych (np. z wykorzystaniem skryptów bash). Następnie uruchomić je na bazie ES za pomocą aplikacji wykorzystujących narzędzie curl. W celu weryfikacji działania należy wyciągnąć wszystkie zdarzenia, które dotyczyły bazy w danym przedziale czasowym.
Analiza klastra ES na środowisku produkcyjnym
Kontynuacja analizy klastra ElasticSearch na środowisku, możemy zacząć od kilku kluczowych elementów, które mogły wpływać na jego wydajność:
- sprawdzenie, jakie zasoby zużywają poszczególne węzły klastra w czasie największego obciążenia,
- zweryfikowanie konfiguracji Javy,
- zanalizowanie logów bezpośrednio z poszczególnych węzłach,
- zweryfikowanie, czy shardy są równomiernie rozłożone na węzłach, ponieważ prawidłowe rozmieszczenie shardów pozwala na optymalne działanie klastra,
- sprawdzenie ilość puli wątków na każdym z węzłów w danym czasie, równomierne obciążenie każdego węzła jest kluczowe dla efektywnej pracy klastra.
Rozmieszczenie shardów należy sprawdzić poniższym zapytaniem:
Przykładowy wynik:
Interwał indeksacji
Aby poprawić wydajność bazy danych, należy również zmienić parametr odpowiedzialny za odświeżanie indeksów. Zmiana w badanym przypadku dotyczyła parametru index.refresh_interval w trybie dynamicznym (bez restartu klastra) z 1s na 30s, jak niżej:
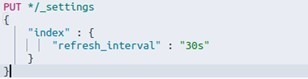
W rezultacie po zmianie otrzymano lepsze czasy indeksacji.
Niemniej w opisywanym przypadku nie przełożyło się na poprawę czasu wykonywania zapytań.
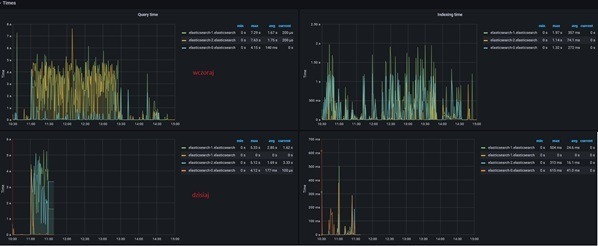
Przykładowe statystyki na Grafanie po wprowadzeniu zmian w indeksacji.
Garbage Collector
Kolejnym element, który może poprawić wydajność klastra ES jest zmiana parametrów GC.
Moduł Garbage Collectora automatycznie wykrywa, kiedy obiekt nie jest już potrzebny i usuwa go, zwalniając miejsce w pamięci przydzielone temu obiektowi bez wpływu na obiekty, które są nadal używane.
W przypadku Garbage Collectora można wdrożyć:
- dodanie zasobów pamięci,
- podniesienie wartości ES_JAVA_OPTS.
W rezultacie można otrzymać mniej uruchomień GC w konkretnym przedziale czasowym.
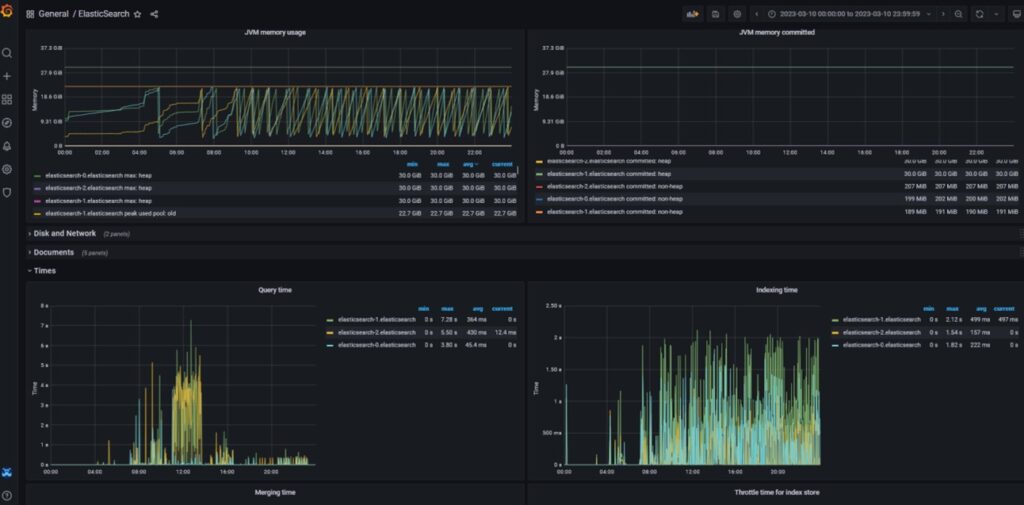
Statystyki GC i Query Time na Grafanie po wprowadzeniu zmian.
Konfiguracja dodatkowego węzła w klastrze
Kolejnym elementem, który może poprawić wydajność klastra ES jest dodanie nowego węzła.
Dodanie kolejnego węzła do klastra ma celu poprawienie wydajności poprzez skierowanie ruchu na dodatkowe zasoby, co odciąży pozostałe węzły. Konfigurację należy wykonać przez zmianę liczby replik. Shard-y rozkładają się automatycznie, a dodatkowy węzeł automatycznie zacznie współpracować z pozostałymi w przetwarzaniu danych.
Konfiguracja wykonuje się poprzez zmianę wpisu dotyczącą ilości replik w konfiguracji elasticsearch.yaml, przykład konfiguracji poniżej:
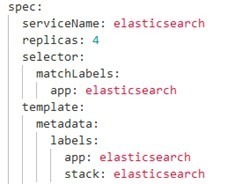
Propozycja innych rozwiązań w celu poprawy wydajności
Inne możliwe rozwiązania, można zrealizować po dodaniu kolejnego węzła:
- Wytypować indeksy występujące najczęściej przy problematycznych zapytaniach, na wybranych indeksach należy zwiększyć liczbę replik.
- Zwiększyć ilość shardów dla poszczególnych indeksów. Można do tego zastosować mechanizmy Split Index API lub Reindex API. Indeksy na czas zmian muszą przejść w stan read-only co będzie wymagało dobrego zaplanowania.
FAQ
Długi czas wykonywania zapytań może wynikać z dużego obciążenia klastra, nierównomiernego rozmieszczenia shardów, niewystarczających zasobów pamięci, nieoptymalnej konfiguracji JVM, częstego uruchamiania Garbage Collectora lub zbyt intensywnej indeksacji danych. Dlatego analiza problemu powinna obejmować zarówno zapytania, jak i konfigurację całego środowiska.
Odtworzenie klastra Elasticsearch na środowisku deweloperskim pozwala bezpiecznie przeprowadzać testy wydajnościowe bez ryzyka wpływu na środowisko produkcyjne. Dzięki temu można sprawdzić, jak system reaguje na określone zapytania, większe obciążenie oraz zmiany konfiguracyjne przed wdrożeniem ich na produkcji.
Prometheus umożliwia zbieranie metryk z klastra Elasticsearch, a Grafana pozwala je wizualizować w formie czytelnych wykresów i dashboardów. Dzięki temu administratorzy mogą obserwować między innymi czas odpowiedzi zapytań, zużycie zasobów, liczbę uruchomień Garbage Collectora czy obciążenie poszczególnych węzłów klastra.
Zmiana parametru index.refresh_interval może poprawić wydajność indeksacji, ponieważ indeksy są odświeżane rzadziej, a klaster zużywa mniej zasobów na ten proces. Nie zawsze jednak przekłada się to bezpośrednio na krótszy czas wykonywania zapytań, dlatego po każdej zmianie należy przeprowadzić pomiary i porównać wyniki.
Dodanie kolejnego węzła warto rozważyć wtedy, gdy obecne węzły są stale przeciążone, zapytania wykonują się zbyt długo, a dostępne zasoby nie wystarczają do obsługi ruchu. Nowy węzeł może pomóc rozłożyć obciążenie, zwiększyć wydajność klastra i poprawić stabilność działania systemu.

Konrad jako wiceprezes Core Logic odpowiada za rozwój rozwiązań technologicznych wspierających wzrost biznesu klientów. Ma ponad 20-letnie doświadczenie w branży IT, obejmujące prowadzenie ambitnych projektów związanych z budową, skalowaniem i zabezpieczaniem infrastruktury IT. Specjalizuje się w obszarach DevOps, mikroserwisów i rozwiązań chmurowych. Łączy perspektywę technologiczną z biznesową, dzięki czemu potrafi przekładać złożone potrzeby organizacji na stabilne, bezpieczne i efektywne systemy.
Porozmawiajmy
Jesteś gotowy, aby razem rozpocząć Twoją cyfrową podróż? Wypełnij nasz formularz lub skontaktuj się z nami telefonicznie.